My second brain setup
How I set up a private Markdown-first second brain with semantic search, AI agents, raw capture, and quiet automation.
I do not want a perfect note-taking system. I want a system that remembers things I will otherwise forget, finds them when I need them, and stays out of my way when nothing changed.
That is the whole design goal of my second brain.
It has three jobs:
- Capture raw information quickly.
- Turn durable things into readable notes.
- Let an agent search, reason, and act on top of it without spamming me.
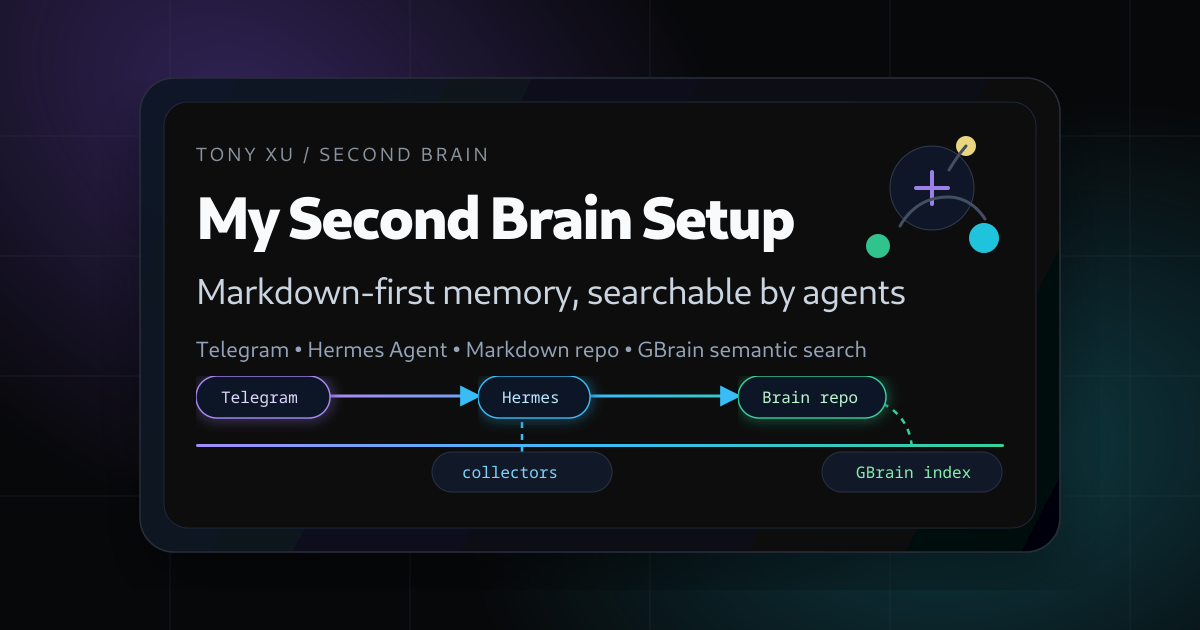
The setup is not fancy in the consumer-app sense. It is a private Markdown repo, a semantic index, a few collectors, and an AI assistant that lives where I already talk to it: Telegram.
The high-level architecture
The system has two main layers.
The first layer is a private Markdown repo. This is the canonical source. If something matters, it should eventually exist as a file I can open, read, diff, and back up.
The second layer is GBrain, my searchable memory layer. It indexes the Markdown files, stores embeddings, and gives agents semantic recall. I treat it like a read/search acceleration layer, not the source of truth.
On top of that sits Hermes Agent, my personal assistant. Hermes talks to me through Telegram, runs scripts, reads the brain repo, searches GBrain, manages cron jobs, and writes back to the right place when I ask it to remember something.
So the shape looks roughly like this:
Telegram
↓
Hermes Agent / Toby
↓
Markdown brain repo ←→ GBrain semantic index
↓
Collectors, scripts, cron jobs, drafts, briefingsThe important part is the arrow direction. Markdown stays canonical. The database is useful, but disposable. If the index breaks, I can rebuild it from the files.
The folder model
The repo is organized around how I actually need to retrieve information later.
brain/
people/
projects/
notes/
daily/
sources/
state/
scripts/people/ and projects/ are the highest-signal areas. They contain durable synthesized pages: who someone is, what the relationship is, what changed, what open loops exist.
notes/ is the main human reading surface. It has personal notes, family/home notes, work notes, knowledge notes, records, and writing drafts.
daily/ is for rendered day-level ledgers. This is where passive activity can become something browsable.
sources/ is provenance. Email digests, calendar exports, liked videos, social activity, Notion exports, and similar raw or semi-raw material live there. I do not want to read most of this manually, but I want the system to be able to trace claims back to it.
state/ is boring and should stay boring: collector progress, sync state, debug output.
scripts/ is the machinery.
The read priority is explicit:
people/andprojects/- curated
notes/ - compiled digests
- raw
sources/ state/
That priority matters. If a durable project page says one thing and a raw export says another, the right move is not to blindly trust the latest blob. The right move is to inspect the source and update the durable page with a dated note.
Raw capture first
Most personal knowledge systems fail because they ask for too much structure at capture time.
I do not want to decide the perfect taxonomy while walking, feeding a baby, or half-reading an article at 11pm. I want to send a message and move on.
So I use a raw-first capture rule.
If I send:
memo: <something>Hermes appends the exact text to a dated personal memo file.
If I send:
limemo: <something work-related>Hermes appends it to a dated work memo file.
The raw text is preserved before interpretation. No rewriting. No summarizing. No pretending a rough thought is already a polished note.
Later, the system can promote the item if it deserves more structure. A saved link might become a knowledge note. A recurring obligation might update a project page. A half-formed idea might become a writing draft. But it does not have to. Raw-only is a valid final state.
That last sentence is more important than it sounds. A second brain should not turn every fragment into homework.
Curation levels
I use a small routing model to avoid over-organizing:
C0: no durable write
C1: raw only
C2: promotion queue
C3: structured note
C4: people/project update
C5: public-writing candidateC0 is for transient logs, one-off task progress, failed attempts with no reusable lesson, and anything sensitive that should not enter memory.
C1 is the default for rough memos.
C2 is for things that smell useful but do not have an obvious home yet.
C3 is a real note under notes/.
C4 updates a canonical person or project page.
C5 means the idea might become public writing, usually a draft for the blog, X, or LinkedIn.
This keeps the system from doing the classic productivity-app thing where the taxonomy becomes more impressive than the thinking.
Search is semantic, but verification is file-based
Semantic search is great for recall. It is not great as the final source of truth.
When I ask Hermes about something non-trivial, the ideal flow is:
- Search GBrain for recall.
- Read the canonical Markdown file.
- Check source exports if the note may be stale.
- Answer with uncertainty if the evidence is thin.
This gives me the benefit of embeddings without letting the embedding layer become the truth layer.
GBrain can answer, “I remember a page about that.” Markdown answers, “Here is what we actually wrote down.”
Collectors: useful, but bounded
Some data enters the system automatically.
I have collectors for things like email/calendar digests, social activity, saved or liked content, and daily activity ledgers. The point is not to hoard everything. The point is to make future recall and writing easier.
For example, likes and saved items are not treated as claims I made. They are taste signals. They can help rank what I may care about, but they are not endorsements.
That distinction keeps the system honest. Passive behavior is context, not belief.
The collectors also follow a quiet-success rule. If everything is healthy, I do not need a notification. If something breaks, I want a concise alert with the broken component and the next best action.
No news is a feature.
The agent layer
Hermes is the execution layer. I call mine Toby.
The job is not just chatting. Toby can:
- capture notes into the brain repo;
- search GBrain and read source files;
- draft emails, posts, and blog ideas;
- run daily briefings;
- check whether collectors are healthy;
- update notes and skills when a workflow changes.
The boundary is simple: low-risk, reversible, verifiable actions can be done directly. Anything that sends, publishes, deletes, changes credentials, or has external consequences requires confirmation.
That means Toby can draft a LinkedIn post from my notes. It cannot publish it without me.
It can label email according to an approved rule. It cannot send a sensitive reply on its own.
It can update a project note. It cannot silently change where private data gets delivered.
Autonomy is useful only if the blast radius is small.
Privacy rules
A second brain can become a self-inflicted surveillance system if you are sloppy.
My rules are intentionally boring:
- Secrets, tokens, cookies, OAuth material, database URLs, and recovery codes do not go into normal notes or semantic search.
- Sensitive records have a separate private area and are not broadly imported or embedded.
- Company-internal material is not casually scraped into personal automation.
- Public drafts are downstream artifacts, not automatic outputs.
- Deleting or publishing requires explicit confirmation.
The goal is not to maximize ingestion. The goal is to preserve useful memory without creating a future data leak.
Why Markdown
I keep coming back to Markdown because it is boring in the right ways.
It works with Git. It can be read without an app. It can be indexed by anything. It has diffs. It survives tool churn.
Databases are great for retrieval. Apps are great for UI. Agents are great for doing work. But the durable memory should live in a format that does not need any of them.
This is also why I do not want the second brain to be only an AI chat history. Chat history is useful, but it is not a knowledge base. It is too noisy, too chronological, and too hard to curate.
A good memory system needs compression. Not lossy LLM summary everywhere, but human-readable distillation: durable pages, dated notes, source links, and explicit uncertainty.
What this gives me
The biggest win is not that I can search old notes. That is table stakes.
The bigger win is that I can ask an agent to operate against my actual context:
- What changed since yesterday?
- What should I follow up on?
- What did I save about this topic before?
- Which project page is stale?
- Turn these raw fragments into a draft, but do not publish it.
- Check the source before answering.
That last one is the difference between a chatbot and a useful assistant.
A chatbot answers from its latent memory. A second-brain agent answers from my memory, with receipts.
What still needs work
The system is useful, but not done.
The hard parts are not the embeddings or the repo structure. The hard parts are maintenance loops:
- stale notes;
- old promotion-queue items;
- collector failures;
- duplicate source exports;
- deciding what deserves curation;
- keeping private data out of the wrong layers.
This is where I think the agent matters most. Not as a magical brain, but as a janitor with taste. Check health. Surface drift. Propose promotions. Stay quiet when nothing changed.
My current opinion
A second brain should be less like a museum and more like a workshop.
The museum version tries to catalog everything beautifully. It feels good for a week and then becomes guilt.
The workshop version is messier. There are raw bins, labeled shelves, unfinished drafts, and a few tools that actually get used. But you can find things. You can make things. You can recover context after life interrupts you.
That is what I want.
Not a perfect archive. A private operating system for memory.
Comments are hosted on GitHub for reliable, searchable threads.
Open comments